Issa B.
English (ZA), Narration
Cameron S.
English (US) Narration
Jay S.
English (US), Narration
Paige L.
English (US), Conversational
Joe F.
English (US), Narration
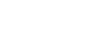









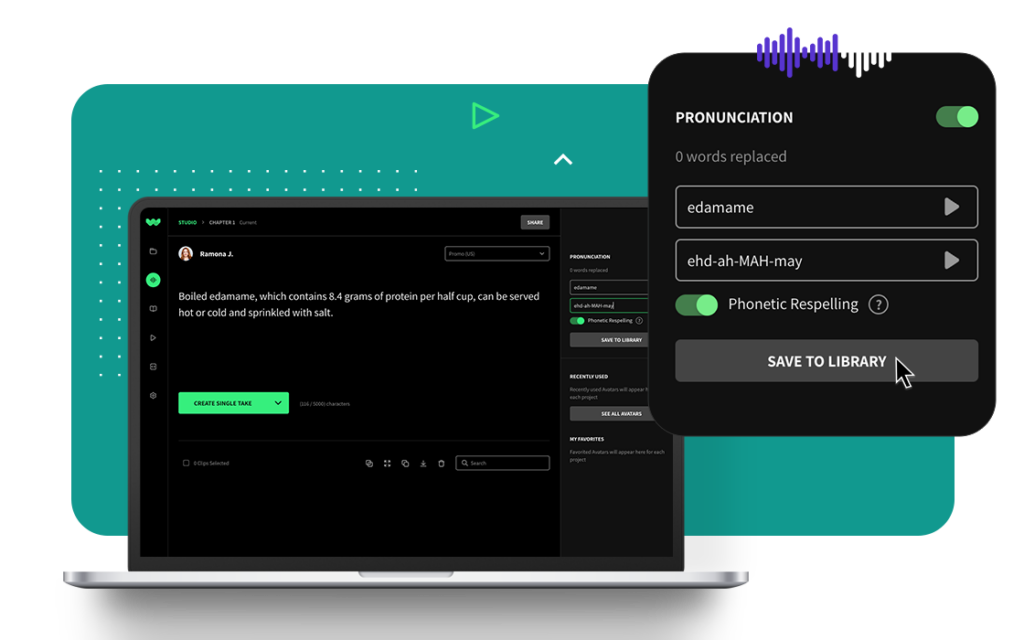
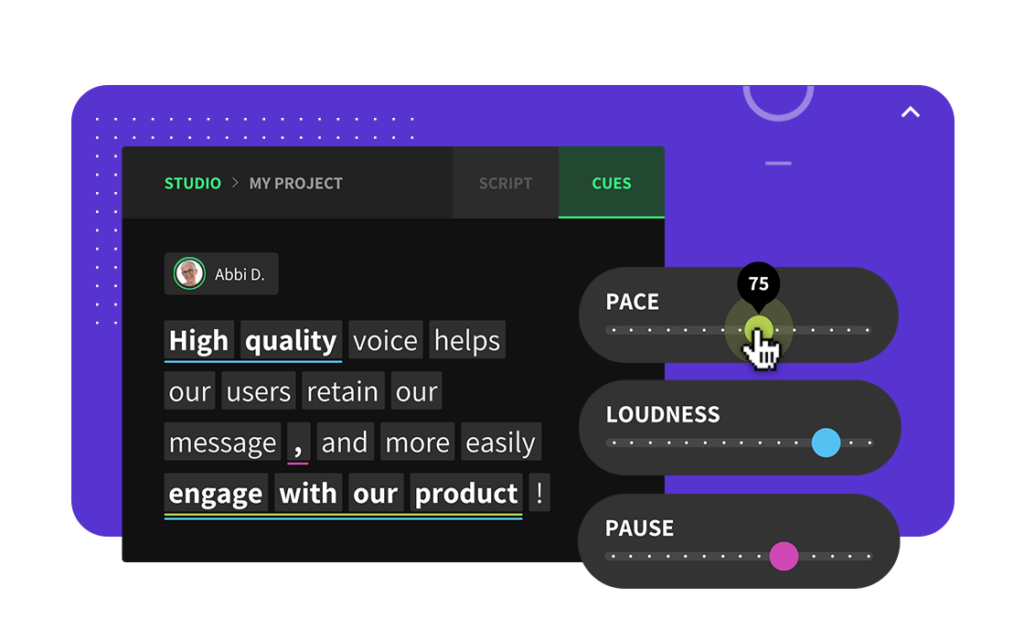


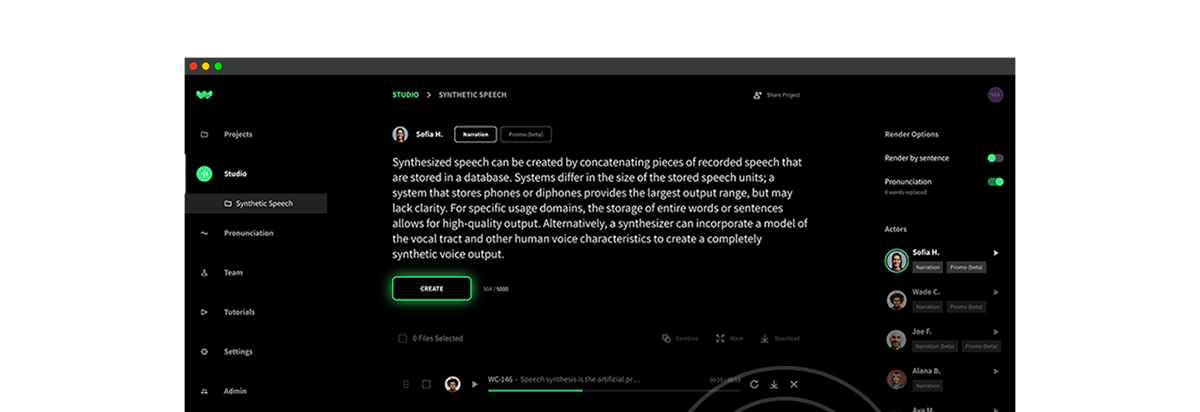
The ideal voice is now available for every product interaction, and every story told. Our expansive library is a trove of voices suited for any project—from immersive creative stories to training modules. Whether you're looking for a male, female, or non-binary voice, the diversity of our AI voice offerings ensures you find the sound that best aligns with your project's needs and brand. We aim to empower you with the most reliable AI voice generation platform you can trust to build great experiences and content to captivate your audiences.
Every story demands a distinct voice, whether a heartfelt advertisement or an informative eLearning course. With our AI voice maker, you're not just getting a voice; you're finding the one that aligns with your content's purpose, ensuring it stands out and leaves a lasting impact.
Now, say that ten times faster. Our voice generation platform creates content 10 times faster than real-time. That means that 60 seconds of narration takes 6 seconds to render. Our AI voices provide the most reliable integration for conversational experiences, IVR, chatbots, and other applications that must react to user interactions.
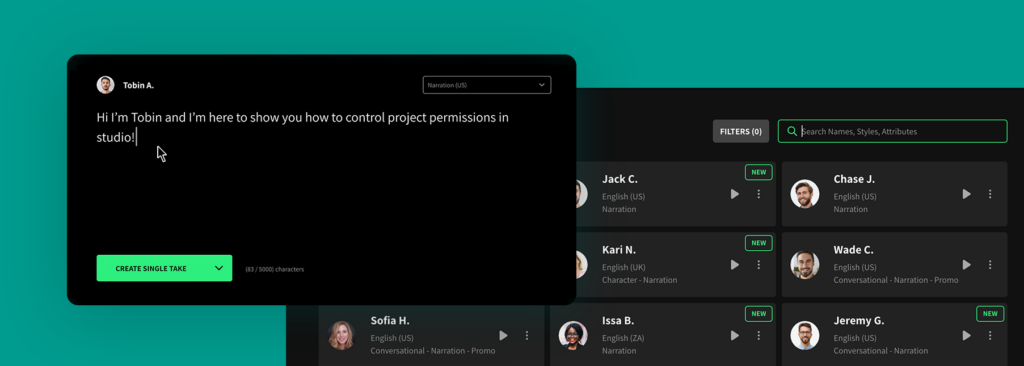
For companies aiming to elevate their internal corporate training modules, our AI voice generator offers an impeccable balance of clarity and engagement. It's about more than imparting information. It's about ensuring every employee remains engaged, understands, and retains critical information to do their job successfully.
In advertising, capturing attention is crucial, but creating a lasting impression is key. We enable you to speak directly to your audience with localized and personalized voice overs, delivering dynamic content at unparalleled speed. Tailor your voice over to amplify your message and ensure your brand stays front of mind.
Voice-guided experiences are the next frontier. Whether it’s creating immersive experiences within apps, or developing user-friendly interfaces, we ensure seamless integration of high-quality text-to-speech technology. Bring your product roadmaps to life, enhance the user experience through our industry-leading voice solutions.
Increase engagement on your video content with our bespoke AI voices. From succinct marketing clips to extensive cinematic projects and everything in between, our AI voice generator is reshaping video production. With a variety of voices adaptable to any theme or mood, ensure your content is deeply engaging.
High-quality voice solutions without the complexity of CMS and DSP integrations. Our AI-driven voice technology effortlessly turns your editorials and blogs into accessible and engaging audio content. Amplify your ad inventory by increasing air time and monetization opportunities. Turn blogs and editorials into audio.
Unlock the full potential of your narratives with WellSaid’s AI voice technology—specially catered to meet the demands of audiobook creators. We transform your written words into vivid audio experiences, maintaining the core spirit of each story while keeping listeners hooked and ever-eager for the next chapter.